Client: Manufacturing Business, Bayshore, New York
Size: 75 employees | 15 workstations | 1 primary server
Client Profile
The client is a mid-sized manufacturing business based in Bayshore, New York. Their operation depends on a centralized server environment supporting production systems, finance, and shipping, including a highly customized ERP platform that has evolved over more than three decades.
The company operates on tight shipping schedules, with year-end and Christmas deadlines representing a critical business period.
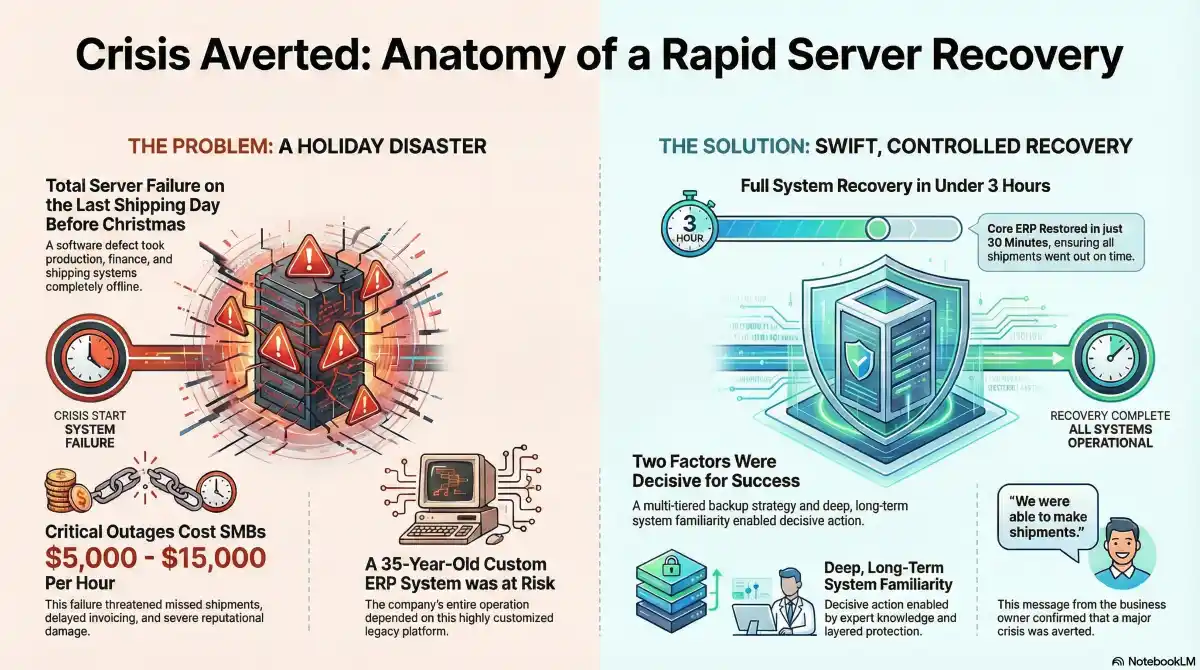
The Incident
In the early hours of a key operational day—the final shipping day before Christmas—a software defect within VMware ESXi caused the system’s data drives to present as failed, rendering all virtual machines offline.
By the time staff arrived on site, production, finance, and shipping systems were unavailable. As a result, the outage threatened missed shipments, delayed invoicing, and failure to complete year-end reporting.
Data Loss and Downtime Costs: Industry Context
To frame the potential business impact:
Downtime is expensive: For small-to-medium businesses, critical IT outages typically cost between $5,000 and $15,000 per hour when accounting for lost revenue, idle workforce, expedited recovery costs, and customer relationship damage. For a manufacturer with 75 employees during peak shipping periods, even a four-hour outage could exceed $20,000 in direct and indirect costs.
Data loss bears broader costs: Beyond immediate financial impact, prolonged outages contribute to missed contractual deadlines, reputational damage with key accounts, and cascading effects on year-end financial reporting.
In this context—even a short outage during a peak business window could have translated to a meaningful hit to annual performance, particularly in manufacturing where production and shipping cadence are tightly scheduled.
Detection and Initial Response
Our automated overnight backup system detected the incident through a failure alert. Shortly after staff arrived on site, the client contacted our office directly.
Within minutes, remote diagnostics confirmed the scope and nature of the failure. We immediately initiated a conference call with the client’s operations manager to assess impact, align expectations, and authorize immediate remediation.
Given the business-critical timing, we decided to bypass prolonged troubleshooting and proceed directly with a controlled system restoration.
Recovery Execution
We prepared a pre-staged server from our inventory immediately. We installed additional drives, configured the appropriate operating system, and transported the system to the client site.
On arrival, we restored the client’s primary virtual machine—running a highly customized ERP system in continuous use for over 35 years—using a tiered backup architecture combining local NAS-based system imaging and redundant cloud replication.
- Core ERP system restored within 30 minutes of arrival on site
- Full system recovery completed in under three hours from initial report
- Desktop systems operational within 60 minutes
- Shipping operations resumed in time to meet UPS cut-off deadlines, preserving Christmas deliveries
Business Outcome
Despite a complete server outage, the company experienced minimal operational disruption. Consequently, all shipments were completed, invoicing proceeded as scheduled, and year-end obligations were met without exception.
“Thanks again for the quick response today. We were able to make shipments.”
— Business Owner, 7:30 PM, day of incident
Following restoration, we briefed senior management immediately and put an agreed plan in place to address short- and medium-term infrastructure improvements.
Why the Recovery Succeeded
Two factors were decisive:
Backup Architecture
A multi-tiered backup strategy combining local system imaging with off-site cloud redundancy enabled rapid, full-system restoration without data loss.
Long-Term System Familiarity
Having managed the client’s IT environment since 2008, we possessed deep operational knowledge of both modern infrastructure and legacy business systems. This expertise enabled decisive action under time pressure.
Lessons and Next Steps
No system is immune to failure, including newly deployed hardware. However, this incident validated the importance of recovery planning over theoretical uptime.
We anticipate the affected server will be replaced, with additional safeguards implemented to further reduce recovery time in future incidents.
Result:
A potentially quarter-threatening outage was reduced to a controlled, same-day recovery—at the most critical point in the client’s calendar year—preserving revenue, commitments, and operational continuity.
Protect Your Business from Downtime
Critical server failures don’t wait for convenient timing. Is your backup architecture tested and ready? Schedule a free infrastructure assessment to identify vulnerabilities before they become emergencies.